CoalescingMergeTree:列级合并,一行成景

CoalescingMergeTree:列级合并,一行成景
王一川CoalescingMergeTree 引擎通过追加写的方式,为 ClickHouse 带来了真正的列级更新能力。作为 MergeTree 家族的新成员,它能够在后台合并时,把稀疏的局部记录逐步聚合成完整行,非常适合以下场景:
- 需要高效保留每个实体的最完整版本
- 可接受后台合并时才落盘整合的延迟
- 只想填补缺失字段,而非像 ReplacingMergeTree 那样整行覆盖
CoalescingMergeTree 首发于 25.6 版本,25.7.2.54 已具备完整更新能力。详情查看issue #84116
一、实现原理
1.1 八股文版
与其它 MergeTree 引擎一样,需要先通过 ORDER BY 声明排序键(主键)。CoalescingMergeTree 会把相同排序键的多条记录做合并,规则:每列保留最新的非 NULL 值,最终在磁盘上得到一行“完整”数据。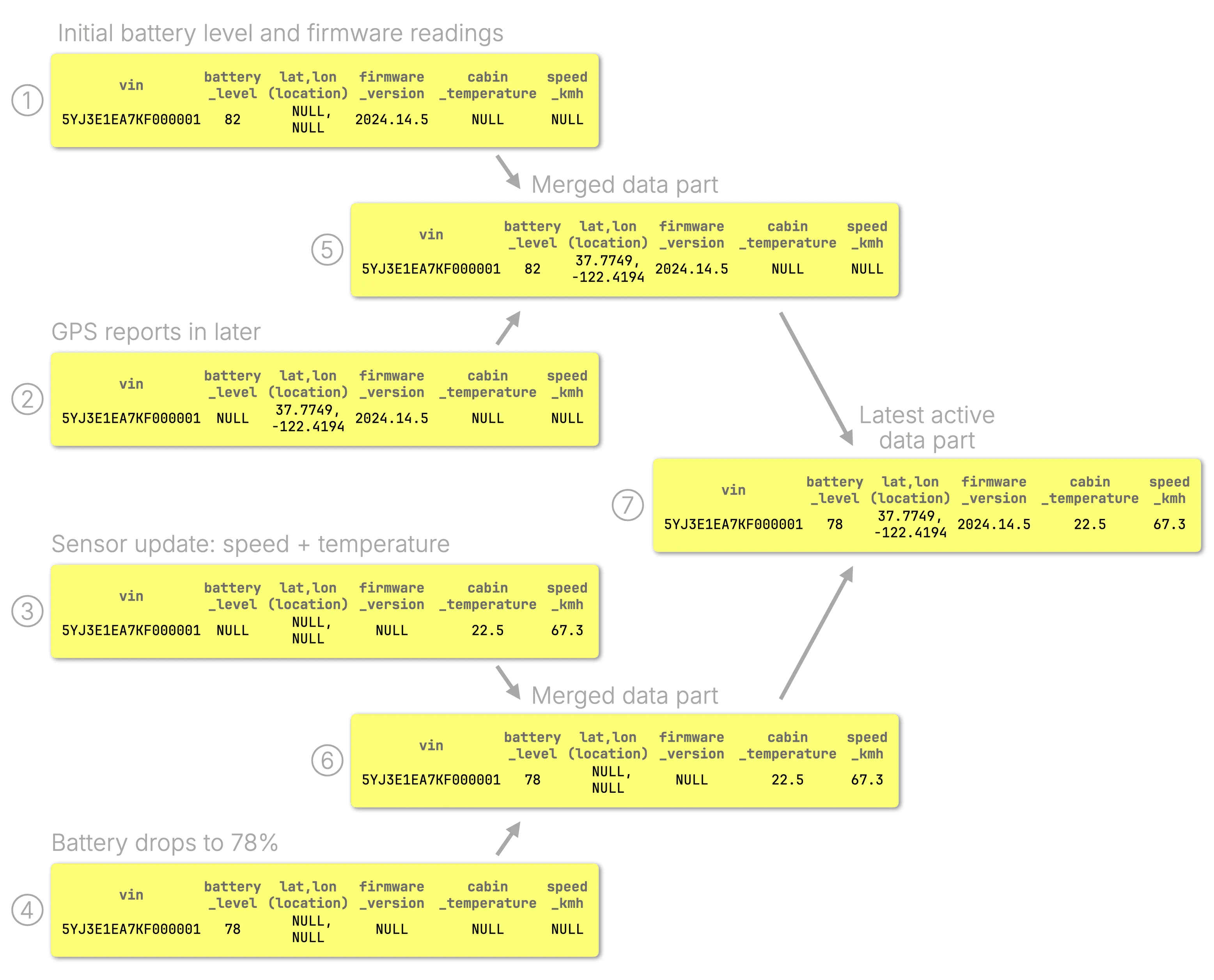
其中 1- 4 为数据 insert 过程,对于同一个 vin 每次插入局部数据
- 初始化 vin 的电池电量和防火墙信息
- 更新 GPS 数据(本质上是插入追加操作)
- 更新速度和温度数据
- 更新电池电量
其中的 5 - 6 为 MergeTree 的局部合并, 7 则将若干个 part 合并成一个 active part 并进行落盘,其中的合并逻辑为:取每列最新的非 null 数据。tip: 这里的最新指的是行插入的顺序,并非依据排序列或者人为指定的列。
1.2 解剖版:用 SQL 讲清楚
如果上面仍显抽象,下面用最简 SQL 演示其本质。
首先是对“最新”的解释:可以理解成 clickhouse 为每一行都分配一个默认值为 now() 的虚拟插入时间。
建表(演示用,非 CoalescingMergeTree)
create table demo |
追加式更新
insert into table demo(id, name, age) values (1, '张三', 20); -- 初始化 id: 1 数据 |
明细数据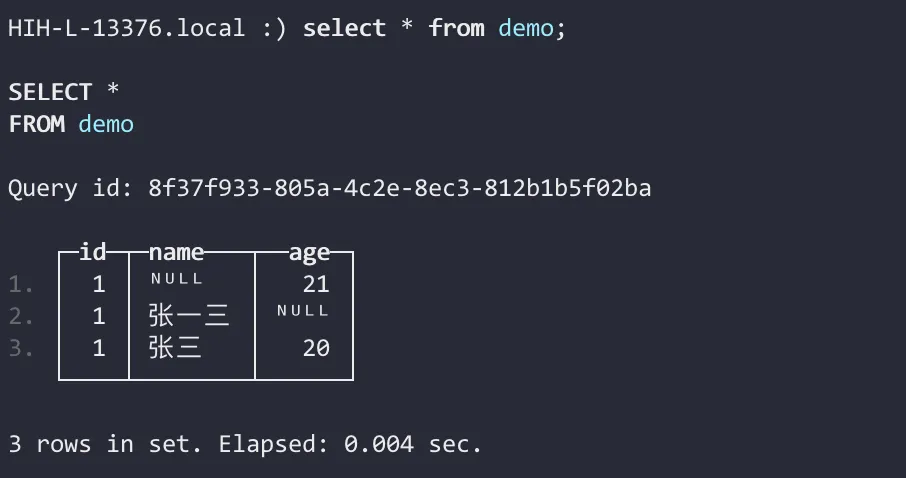
CoalescingMergeTree 的合并逻辑等价于
select |
若把该语句封装成物化视图,即可模拟 CoalescingMergeTree;而 CoalescingMergeTree 只是把这个过程内嵌到了 MergeTree 的合并阶段。
二、实战
CoalescingMergeTree 特别适合局部更新场景,例如官网给出的 Tesla 在车联网上的应用。我们知道 clickhouse 在超大宽表的查询上性能极高,但超大宽表中每个数据域的就绪时间往往是不同的,企业中为了让 clickhouse 中宽表的可用时间尽可能长采用局部分批更新策略,使用 CoalescingMergeTree 将会变得更加方便
2.1 构建环境
- 宽表:
user_profile_wide(CoalescingMergeTree) - 分域表:
user_profile_basic / behavior / business(MergeTree)
create table user_profile_wide |
为了方便进行局部数据更新,以及对不同主题域 ETL 任务的拆分,每个域的数据在 clickhouse 中都有一张表
create table user_profile_basic |
2.2 构建数据管道
每个分域表只负责追加写入,宽表通过物化视图自动合并
create materialized view mv_user_profile_basic to user_profile_wide as |
至此!一个借助 CoalescingMergeTree 实现的大宽表局部更新数据管道就构建好了
2.3 演示更新
分三批将三个主题域的数据写入主题表中,每一批写入之后都可以查询一下宽表
insert into user_profile_basic |
因为更新操作是发生在 MergeTree 的合并过程中,通常在查询时需要加上 final 关键字保证数据的一致性
select * from user_profile_wide final; |
后续如果想要更新某个字段的值只需要向对应字段插入数据即可
insert into tblxxx(id, colxxx) values(1001, valuexxx); |
三、注意事项
因为 CoalescingMergeTree 判断字段不更新的逻辑是 null,因此 DDL 中除了排序键外所有的字段必须要是 Nullable 修饰的数据类型,如果所有字段类型都不使用 Nullable 修饰则与 ReplacingMergeTree 功能一致,即:整行替换
那么与 ReplacingMergeTree 的区别如下:
| 维度 | CoalescingMergeTree | ReplacingMergeTree |
|---|---|---|
| 设计目的 | 逐列合并,减少行数,节省存储 | 多记录去重,保留最新一行 |
| 合并粒度 | 列级 | 行级 |
| null 值处理 | 表示未更新,合并时被非 null 覆盖 | 与普通值一样不做特殊处理 |
| 是否丢列 | 不会丢失任何已写入的列值 | 未出现在新行里的列值会丢失 |
其次,一定要注意数据乱序对 CoalescingMergeTree 的影响特别是在高频数据场景中,因为 CoalescingMergeTree 的局部更新逻辑依赖物理插入顺序,建议:
- 同一实体短时间内避免多批次并行写入
- 统一 ETL 作业,显式控制写入顺序
同时 clickhouse 的局部更新方案远不止如此,点击卡片了解更多
文末留个小问题:为什么 CoalescingMergeTree 要求使用 Nullable 数据类型?












