别再让 Excel 毁了你下班前的灵感

别再让 Excel 毁了你下班前的灵感
王一川写给所有把数据仓库当“一次加工”,把本地电脑当“二次战场”的数据人
先来三个灵魂拷问
- 你上一次把 ADS 表导出 Excel 做探查,是不是卡到风扇起飞?
- 你上一次 vlookup 三张百万行 CSV,是不是蓝屏死机?
- 你上一次把 Excel 粘给老板,是不是被问“能不能换个格式,我要透视”?
如果你都点头,那恭喜你——你已经在做“二次分析”了
而二次分析,正是DuckDB在今天依旧值得被数据人放进工具箱的最大理由。
一、闲谈
1.1 什么是二次分析
| 维度 | 一次加工 | 二次分析 |
|---|---|---|
| 位置 | 数仓/Hadoop/Spark | 本地电脑 |
| 产出 | dwd/dws/ads 表 | 业务问题的答案 |
| 工具 | hive/spark/flink等 | excel/python/r |
| 量级 | TB级 | GB及以下 |
| 目标 | 口径对齐与沉淀 | 灵活探查与试错 |
一句话总结:数仓把数据做对,DuckDB把数据做活
1.2 为什么能赢 Excel
| 维度 | Excel 2021 | DuckDB 1.3 |
|---|---|---|
| 单文件上限 | 1,048,576 行 | 无硬性限制(受内存) |
| CSV 读取 | 慢、类型推断错 | GB/s+、自动推断 |
| SQL 支持 | PowerQuery 半吊子 | 完整 SQL:2016 |
| 多表关联 | vlookup | 标准 JOIN |
| 窗口函数 | 不支持 | 全支持 |
| 可脚本化 | VBA | Python/R/CLI等 |
| 结果导出 | xlsx/csv/txt | parquet/json/xlsx等 |
ps: 表格数据来自 AI 总结
另外在文件读取上,DuckDB 支持 parquet/avro/xlsx/csv 等文件自动推断,包括文件类型和 schema 推断
二、上手
2.1 安装
通用脚本安装
curl https://install.duckdb.org | sh |
点击查看更多安装方式
不会装?那直接使用 wasm 版本吧!!!点击前往(注意数据安全问题哦)
2.2 数据
使用 COVID-19 流行病学公开数据中的
schema等相关信息访问github仓库
2.3 分析
虚拟一个分析场景:
找出过去 30 天内,每百万人口新增确诊最多的前 10 个国家,并给出它们的死亡率(新增死亡 ÷ 新增确诊)与 确诊率(新增确诊 ÷ 人口 × 1,000,000)
如果使用 Excel,嗯…我不会…AI说可以。
个人认为做数据分析最好的形态就是 notebook,一次尝试一个cell清晰简洁。使用duckdb -ui开启它会自动跳转到浏览器,默认地址http://localhost:4213/
新建 notebook -> add cell -> 写sql
-- 假设 epidemiology.csv 和 demographics.csv 已下载到同目录 |
执行结果如下: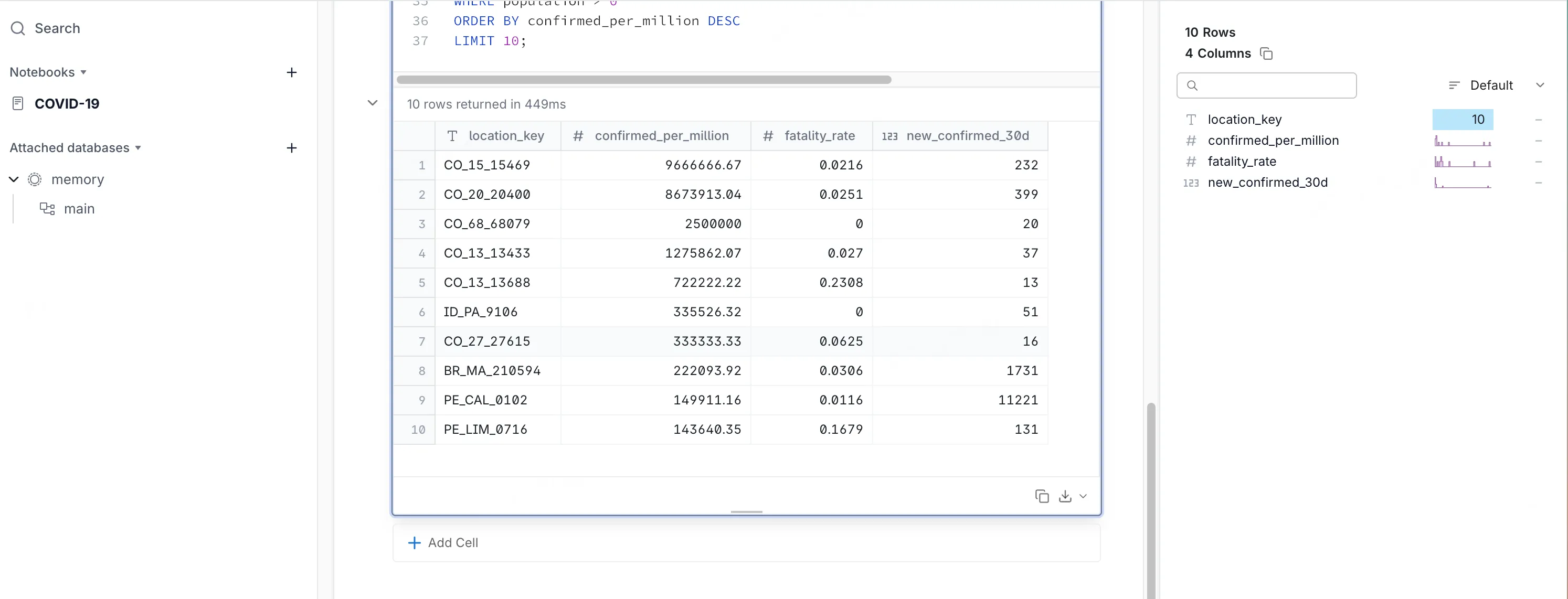
仅500毫秒即可返回结果,同时右侧窗口展示指标的数据分布。
如果先将 csv 写入 duckdb 内部表速度将更快,因为它是列存
三、小结
DuckDB 的能力远不止如此,如果你有一些“奇怪”的权限甚至可以直接读 hive 的分区
例如:orders 是一张二级分区的表
orders |
可以使用下面的sql读取且支持分区裁剪
SELECT * |
同时 DuckDB 的 Extension 机制,让 DuckDB 支持读取 Iceberg、RDBMS、S3 甚至可以做 FTS(full-text search)和 Embedding Stores
总之:别再让 Excel 毁了你下班前的灵感,在二次分析这条赛道,DuckDB 不是“单机玩具”,而是“本地 OLAP 火箭”